对象存储实现分析
1 总体介绍
相比块存储,对象存储对延时要求相对宽松。
对象存储通过HTTP/HTTPS和定制客户端访问。AWS S3, Azure Blob, Google GCS, 阿里云 OSS,是对象存储的典型产品。S3在市场上占主要的份额。除了Azure Blob,其他各家都提供S3兼容的服务。
对象存储一般是典型的三层架构:
- 前端:服务接入层;HTTP/HTTPS服务/客户端;
- 元数据:KV存储,实现ObjectName到ObjectData的映射管理;
- 持久化层:数据持久化。
从论文和公开资料,可以看到Azure Blob和阿里云OSS都是基于底层分布式文件系统的实现。AWS S3没有分布式文件系统层,直接持久化到单机引擎上,引擎实现为ShardStore, LSMTree实现。通过Extent/Chunk,支持Zone类型介质。
对象存储基于分布式文件系统和KV搭建时,核心难点是分区分裂与合并。
考虑硬件生命周期管理,对象存储支持跨集群数据复制/迁移。
1.1 KV选择
开源的KV引擎有LevelDB,RocksDB,TiKV。在KV引擎上构筑分布式的元数据服务,依然存在较多技术点。主要是高可用,负载均衡,分区分裂与合并,性能平稳,故障快速恢复等。在服务可观测性,系统升级等工程层面,也有较多事情要做。
2 AWS
S3独立部署元数据系统与数据系统。之前多个版本提供最终一致性,目前已提供强一致性。
文章Diving Deep S3 Consistency介绍,S3元数据系统是分离的,使用缓存技术提供高的弹性能力。在缓存不可用时,请求依然能成功。
S3数据系统使用ShardStore。ShardStore天然支持Zone介质。Zone称为extent,切分为多个 chunk,chunk顺序写入,类似LSM的追加写。ShardStore在论文<<Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3>>中有提及。下载链接: https://assets.amazon.science/07/6c/81bfc2c243249a8b8b65cc2135e4/using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3.pdf
3 阿里云
阿里云对象存储的优势非常明显。从这里(链接)可以看到,OSS基于女娲、盘古、有巢,以及服务接入,负载均衡构建。
元数据服务是OSS核心组件之一,基于有巢构建。有巢是KV存储引擎,类似LevelDB, RocksDB。 2021年阿里云发布了ArkDB论文(https://dl.acm.org/doi/10.1145/3448016.3457553 ArkDB: A Key-Value Engine for Scalable Cloud Storage Services),这有可能演化为阿里云下一代KV存储引擎。
有巢是什么,阿里云developer上有个问题:
From https://developer.aliyun.com/ask/429009
Q: 有巢分布式 KV的功能是什么?
A: 有巢分布式 KV 实现了多实例冗余的特性,把 KV 分解为由多个副本成的分区组(partition group),该分区组通过一致性协议选举出 Leader 节点对外提供服务,当 Leader 节点故障或出现网络分区时,能够快速选出新的 Leader 节点并接管该分区的服务,从而提升 OSS 元数据服务的可用性。
知乎上有一篇关于OSS SLA背后技术体系的文档:
From https://zhuanlan.zhihu.com/p/157797766
有巢分布式 KV 为 OSS 对象存储提供分布式Key-Value 元数据功能,作为阿里云最早研发的的 KV 系统,历经多年 OSS 的业务打磨,它在大规模集群下有非常深厚的技术积累。2014 年实现了多实例冗余的特性,把KV 分解为由多个副本成的分区组(partition group),该分区组通过一致性协议选举出 Leader 节点对外提供服务,当 Leader 节点故障或出现网络分区时,能够快速选出新的 Leader 节点并接管该分区的服务,从而提升 OSS 元数据服务的可用性,如下图所示。
OSS服务层聚焦数据组织和功能实现,由于底层盘古和有巢的分布式能力,OSS 服务层按照无状态方式设计,从而故障时可以快速切换,提高可用性。但是,由于 OSS是多租户模型设计,做好 QoS 的监控和隔离,是保障租户可用性的关键。
元数据服务通过分区机制实现线性扩展,分区策略一般有Hash-Based和Range-Based两种。从ArkDB论文来看,阿里云基于ArkDB支撑了OSS, NAS, OTS三个核心存储服务。
分区分裂和合并的难点在于分裂同时保证服务的稳定性。
下面这个PR文章也包含较多信息:
From https://developer.aliyun.com/article/766513
提升 10 倍!阿里云对象存储 OSS 可用性 SLA 技术揭秘
OSS 提供了本地冗余存储(部署在一个 AZ)、同城冗余(部署在三个 AZ)存储类型,它们的逻辑架构相同,主要包含如下模块:女娲一致性服务、盘古分布式文件系统、 OSS 元数据(有巢分布式 KV 索引)、OSS 服务端、网络负载均衡等。
同城冗余存储(3AZ)则是在物理架构上是提供机房级别的容灾能力,将用户数据副本分散到同城多个可用区。当出现火灾、台风、洪水、断电、断网等灾难事件,导致某个机房不可用时,OSS 仍然可以提供强一致性的服务能力。故障切换过程用户业务不中断、数据不丢失,可以满足关键业务系统对于 RTO(Recovery Time Objective)和 RPO( Recovery Point Objective)为 0 的强需求。同城冗余存储,可以提供 99.9999999999% (12 个 9)的数据设计可靠性以及 99.995% 的服务设计可用性。
有巢分布式 KV(Key-Value) 元数据
OSS 采用自研的分布式 Key-Value 来保存元数据,它构建在盘古分布式文件系统之上,其大规模集群历经多年的业务打磨,有着非常深厚的技术积累。
有巢分布式 KV 实现了多实例冗余的特性,把 KV 分解为由多个副本成的分区组(partition group),该分区组通过一致性协议选举出 Leader 节点对外提供服务,当 Leader 节点故障或出现网络分区时,能够快速选出新的 Leader 节点并接管该分区的服务,从而提升 OSS 元数据服务的可用性,如下图所示。
4 Azure Blob
Azure Blob是微软云对象存储。
From https://docs.microsoft.com/zh-cn/azure/storage/blobs/storage-blobs-overview
Azure Blob 存储是 Microsoft 提供的适用于云的对象存储解决方案。 Blob 存储最适合存储巨量的非结构化数据。 非结构化数据是不遵循特定数据模型或定义的数据(如文本或二进制数据)。
Blob 存储用于:
- 直接向浏览器提供图像或文档。
- 存储文件以供分布式访问。
- 对视频和音频进行流式处理。
- 向日志文件进行写入。
- 存储用于备份和还原、灾难恢复及存档的数据。
- 存储数据以供本地或 Azure 托管服务执行分析。
Azure Blob在WAS论文里有描述。论文下载链接:
- https://sigops.org/s/conferences/sosp/2011/current/2011-Cascais/printable/11-calder.pdf
- https://azure.microsoft.com/en-us/blog/sosp-paper-windows-azure-storage-a-highly-available-cloud-storage-service-with-strong-consistency/
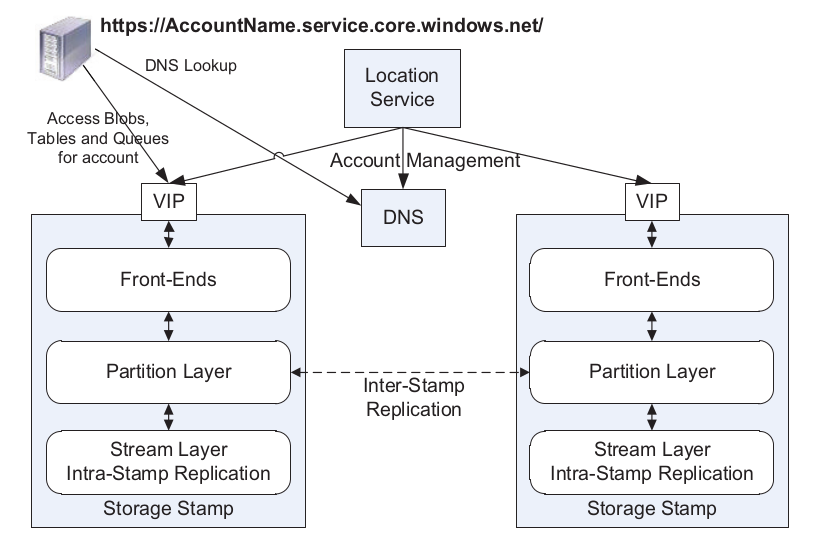
WAS在StreamLayer实现数据持久化,在PartitionLayer实现范围分区的Blob, Queue, Table服务。这些服务基于内部数据结构OT(Object Table),可以达到PB级,支持分区分裂合并。OT支持CRUD 操作,并支持同一个PartitionRange内的BatchTxn。OT提供快照隔离的一致性。快照隔离存在写倾斜问题,业务调用时,应该通过行锁或事务锁加了保护。
OT Schema支持简单的数据类型,bool, binary, string, DateTime, Double, GUID, int32, int64. 以及两个特殊的Type:DictionaryType 和 BlobType。DictionaryType是个(name, type, value)的三元组。BlobType 是外挂数据,数据实际保存在其他位置,这里只存个位置索引,例如,保存多个 (extent + offset, length)。
OT预期是LSM的典型实现:
- MemTable: 一个活动的内存表,WAL持久化,重启需要Replay再生成;
- Immutable: 不可修改的内存表,WAL持久化,重启后需要Replay再生成;多个Immutable合并生成Checkpoint,以节省内存,加速重启加载时间;
- SSTable:有序索引表,可以多级,可以再次合并(Compaction)生成新的SSTable;通过 Bloomfilter加速查找;B+Tree或者BwTree数据结构;
- DataFiles:大的数据可以独立放置,减少Compaction的写放大。
WAS设计提到了几个点:
- 计算存储分离扩展;
- 范围分区;
- 流控与隔离;
- 自动负载均衡;
- 每个分区一套独立的Log文件;
- 日志合并Journaling写入;
- 追加写系统;
- E2E数据一致性检测;
- 可升级设计;
- 一套栈支持多个数据结构抽象(对象,表,队列)
- 怀疑块存储也类似,但有内部信息表示块存储已经切到其他实现;
- 高性能日志;
- 压力测试;
PartitionLayer包括PM和PS。PM负责调度,PS负责一部分分区。
快照隔离需要MVCC支持。WAS没有提及这部分如何实现。
5 Tencent/腾讯
腾讯新一代对象存储系统YottaStore,2018年开始研发,荣获2021年腾讯最高技术奖。
分析YottaStore过程中,看到一篇水分太大没法看的文章:
From https://zhuanlan.zhihu.com/p/276618798
首先,在集群规模上,作为一个云原生的数据存储系统,YottaStore理论上一个集群可以管理超上千万台服务器,而要管理这上千万台的机器,元数据管理只需要用600G左右的空间,仅用一台机器就能存下索引结构,这在业界绝无仅有。
一台管千万台,千万分之一的元数据量,10M数据对应1字节的元数据。这数据太蛋疼,想到了中建四局的优秀员工一年盖7亿次章,华为5G 2000公里0.1毫秒的延时,比光速还快66倍。八卦下,5G超光速视频参见这里:https://www.zhihu.com/zvideo/1488976122217541632
YottaStore另一篇PR文稍微好一点:https://zhuanlan.zhihu.com/p/340834405